Start date: 01-09-2021
End date: 28-02-2022
Clinical Problem
Three dimensional (3D) landmarks are used in various fields within medicine. The 3D landmarks are often used in the alignment of 3D photos. The placement of 3D landmarks is used in the Radboudumc 3D-Lab and the department of Oral and Maxillofacial Surgery for surgical planning, follow-up and diagnostics. Manual placement of 3D landmarks is a cumbersome process with a high degree of inter- and interobserver variability depending on the task at hand. Accurate and consistent landmark placement is key in the planning and follow-up of 3D imaging with landmark based alignment.
Therefore, this work attempts to automize facial landmarking by making use of artificial intelligence (AI). We choose 12 clinically relevant landmarks and manually annotate 307 samples from the Headspace data set, consisting of 3D meshes of faces.
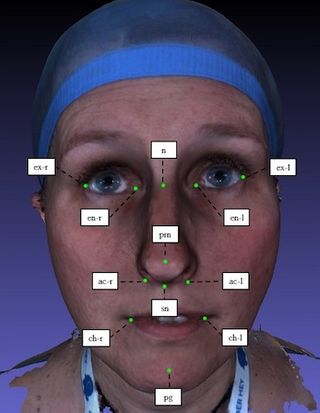
Methods
This work leverages DiffusionNet for surface-learning on point clouds. DiffusionNet is a representation-independent and sampling robust network structure based on heat diffusion. This work presents a point-wise regression method that predicts regions around landmarks with increasing activation closer to the landmark point. The initial network predicts rough landmark positions based on the coordinates with color features or the heat kernel signature. A refinement network is subsequently applied to more accurately locate the landmark based on its neighbourhood sampled in high resolution.
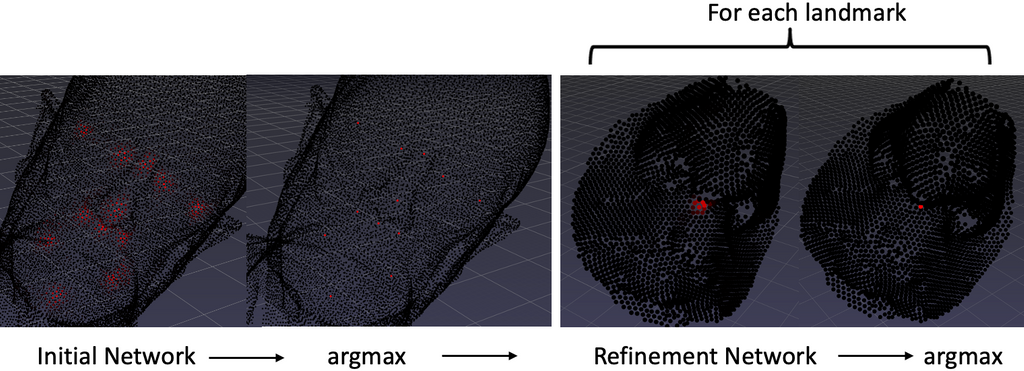
Results
| Landmark | Abbreviation | Mean error in mm |
|---|---|---|
| Pogonion | pg | 2.68 |
| Nasion | n | 2.50 |
| Pronasale | prn | 1.33 |
| Subnasale | sn | 2.29 |
| Alar curvature (right) | ac-r | 1.29 |
| Alar curvature (left) | ac-l | 1.70 |
| Exocanthion (right) | ex-r | 2.05 |
| Endocanthion (right) | en-r | 1.92 |
| Endocanthion (left) | en-l | 2.39 |
| Exocanthion (left) | ex-l | 2.95 |
| Cheilion (right) | ch-r | 2.70 |
| Cheilion (left) | ch-l | 2.83 |
| mean | 2.217 |
The refinement network appears effective as it improves the initial network’s detection accuracy of 2.78mm to 2.22mm. The initial network is trained on coordinate input with color features. Horizontal flipping is applied as data augmentation. Raw coordinate input shows good detection accuracy on faces and craniums that are consistently oriented in space. It was found that the isometry-invariant shape descriptor heat kernel signature yields more suitable input features for faces “in the wild”, where such assumptions cannot be made.
Conclusion
With a mean error of 2.22mm, the landmark detector shows promising results and makes only slightly more inaccurate predictions than a human annotator does. However, the model is limited to consistent head orientations. If that requirement is not met, a model trained on HKS features can enable rotation invariance but shows inferior detection accuracies.
The thesis can be downloaded here.
The code can be found in the GitHub repository.





