During the course you will work on an AI project together with a team for 4 project days. During these days you will go through all the steps that have to be taken to successfully deploy your AI application: context understanding, data understanding, data preparation, modelling, evaluation and deployment. Below you can find example project from previous editions of the course.
Electronic nose device: detection of colorectal cancer through exhaled breath
Esmee Bakker and Yonne Peters worked on Electronic nose device: detection of colorectal cancer through exhaled breath using a non-invasive screening tool. Electronic noses analyze volatile organic compounds in air, in this case, air breathed out by people suspected of colorectal cancer. These e-noses are becoming cheaper and are equipped with more sophisticated sensors. Esmee and Yonne applied different machine learning approaches to the e-nose measurements but concluded that the performance was not yet good enough to consider integrating this in the colorectal cancer screening in The Netherlands.
Predicting re-intubation in critically ill patients
Sabine van den Akker, Tessel Galesloot, Luc Evers, Ruud van Kaam and Tim Frenzel worked on a machine learning approach for Predicting re-intubation in critically ill patients. Many patients in ICU where the tube has been removed need to be re-intubated at a later point in time. A model that accurately computes the probability that re-intubation will be needed could improve patient management. The team showed that data collection at the ICU is challenging, and careful data cleaning is required before machine learning can be applied.

AI for classification of breast cancer in 3D ultrasound data
Ilse Spenkelink, Tom Perik, Loes van der Zanden, Gerben Lassche and Chris de Korte worked with deep learning techniques for image classification in AI for classification of breast cancer in 3D ultrasound data. Building upon standard 2D convolutional networks, they developed a pipeline to classify 3D ultrasound patches.
Fragmentomics
Lisa Hofste, Pascal van Nispen, Milou Schuurbiers and Janet Vos presented Fragmentomics. The team requested all data from a recent Nature publication that introduced a method to diagnose different types of cancer from measurements of cell-free DNA present in the blood. They reproduced the machine learning experiments in the paper and showed that different classifiers obtained even slightly better performance.
Electroconvulsive therapy: predicting the seizure
Amon Heijne, Daan de Jong, Daphne Everaerd and Laurens Verscheijden made an algorithms for Electroconvulsive therapy: predicting the seizure. Patients who receive this treatment undergo multiple sessions. Choosing the right settings for each session is difficult, so sessions sometimes need to be repeated. The team analyzed whether it is possible to better predict the optimal setting based on previous sessions. They concluded that the results they obtained were not yet good enough, but adding additional clinical features might improve the prediction.
Automated clinical scoring in psoriasis
Lex Dingemans, Tom Loonen, Anouk van der Schot and Mirjam Schaap addressed Automated clinical scoring in psoriasis. The severity of disease in psoriasis patients is often quantified with the PASI score. The team presented the first steps towards automatically assessing one aspect of this score from photographs using deep convolutional neural networks. Mirjam Schaap also recently received a Radboud AI Voucher to continue this research.
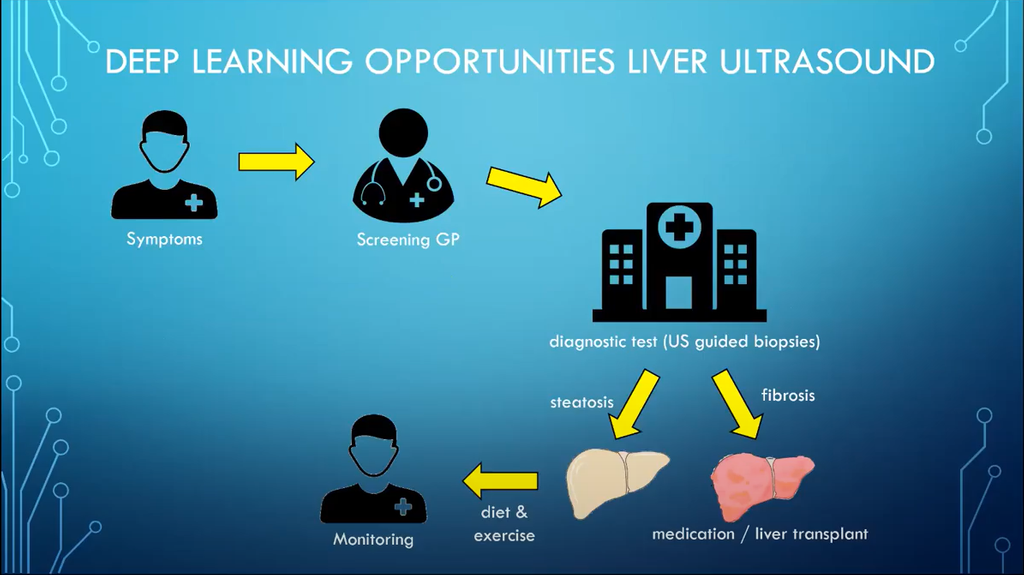
Prediction of steatosis and fibrosis from liver ultrasound using deep learning
Gert Weijers, Jonne Doorduin, Anton Meijer and Jan-Willem Wasmann worked on the Prediction of steatosis and fibrosis from liver ultrasound using deep learning. Liver biopsies are currently necessary in selected patients to identify liver fibrosis, leading to risk of bleeding associated complications. The team created a deep learning algorithm to recognize the steatosis and fibrosis from ultrasound images. The algorithm learned to reliably detect steatosis, but fibrosis was more challenging to identify. More data from fibrosis patients will hopefully improve this in the future.
Classifying patient with inborn errors of metabolism using machine learning
Arjen de Boer, Michael Ricking, Purva Kulkarni and Rob Tolboom worked on Classifying patient with inborn errors of metabolism using machine learning. Mass-spectrometry data is notoriously high dimensional, making it difficult to identify biomarkers for inborn errors. Using dimensionality reduction techniques the team identified several potential biomarkers for inborn errors. Further validation on future data will teach us how valuable these biomarkers are for predicting inborn errors.
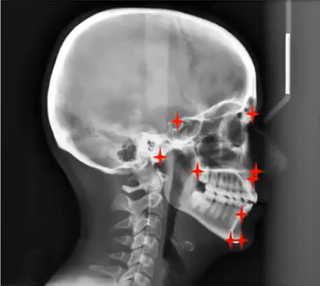
Automatically detect orthodontic landmarks on lateral headplates
Frits Rangel, Charlotte Ijsbrandy, Stan Wijn, Ward de Witte and Stani Sparreboom-Kalaykova created an algorithm to Automatically detect orthodontic landmarks on lateral headplates. Such landmarks provide an orthodontist with important measurements before an intervention, but identifying them takes up valuable time from the orthodontist. Their results showed good performance on a subset of the landmarks, showing potential to fully automate this process.
Predict who might not benefit from mindfulness based cognitive therapy
Fiona Zegwaard, Gijs van de Veen and Dirk Geurts worked on a machine learning approach to Predict who might not benefit from mindfulness based cognitive therapy. This therapy helps to reduce depressive symptoms in many patients, but does not work for a subset of patients. Machine learning could potentially identify patients for whom the treatment is not suited, but the current data set did not provide insights to improve predictions of treatment outcome. To improve the data set potential extra data features have been suggested that could help prediction of treatment outcome.
Predict the length of stay for ICU patients
Maarten Arends, Roberto Garcia van der Westen, Chris Peters, Ingrid van Weerdenburg and Berti Moonen made an algorithm to Predict the length of stay for ICU patients. The planning of operations depends strongly on the predicted length of stay for patients after operation. Currently the length of stay is predicted purely on the type of operation that a patient undergoes. The team tried to improve these predictions by adding more patient data and using a machine learning approach. A slight improvement in predictions was achieved, but further work is necessary to make it a valuable tool on the ICU.